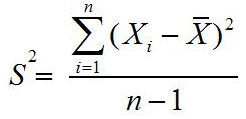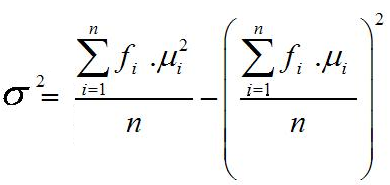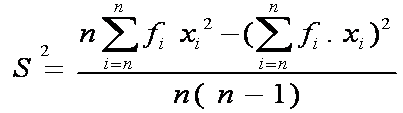BAB 7
PENGUJIAN HIPOTESIS
Hipotesis
: berasal dari kata “hypo” artinya “di bawah” dan “thesa” yang artinya
“kebenaran”. Jadi Hipotesis merupakan
suatu asumsi atau anggapan yang bisa benar atau bisa salah mengenai sesuatu
hal, dan dibuat untuk menjelaskan sesuatu hal tersebut sehingga memerlukan
pengecekan lebih lanjut.
Hipotesis statistik adalah
suatu asumsi atau anggapan atau pernyataan yang mungkin benar atau mungkin
salah mengenai parameter satu populasi atau lebih.
Pengujian
statistik adalah suatu
prosedur yang didasarkan kepada bukti sampel dan teori probabilita yang dipakai
untuk menentukan apakah hipotesis yang bersangkutan merupakan pernyataan yang
wajar dan oleh karenanya tidak ditolak, atau hipotesis tersebut tidak wajar dan
oleh karena itu harus ditolak.
Prosedur lima langkah untuk
menguji suatu hipotesis :

Langkah 1 :
Rumuskan hipotesis nol dan hipotesis alternatif.
¡ Langkah pertama adalah merumuskan hipotesis yang akan
diuji. Hipotesis ini
disebut Hipotesis nol disebut H0 (dibaca H nol).
¡ Hipotesis alternatif menggambarkan apa yang akan anda
simpulkan jika menolak hipotesis nol. Hipotesis alternatif ditulis H1 (dibaca H
satu).
Langkah 2 : Taraf nyata
¡ Taraf nyata diberi tanda a (alpha), disebut juga tingkat resiko karena
menggambarkan resiko yang harus dipikul bila menolak hipotesis nol padahal
hipotesis nol sebetulnya benar.
¡ Tidak ada satu taraf nyata yang diterapkan untuk semua
penelitian yang menyangkut penarikan sampel. Kita harus mengambil suatu
keputusan untuk memakai taraf 0,05
(disebut taraf 5 persen), taraf 0,01, atau taraf yang lain antara 0 dan 1.
¡ Pada umumnya pada proyek penelitian menggunakan taraf 0,05, sedangkan untuk pengendalian mutu
dipilih 0,01, dan untuk pengumpulan jajak pendapat ilmu-ilmu sosial dipakai
0,10.
Langkah 3 : Uji
statistik
¡ Merupakan suatu nilai yang ditentukan berdasar informasi
dari sampel, dan akan digunakan untuk menentukan apakah akan menerima atau
menolak hipotesis.
¡ Ada bermacam-macam uji statistik, di sini kita akan
menggunakan uji statistik seperti z, student-t, F, dan l2 (Kai-kuadrat).
Langkah 4 : Aturan
pengambilan keputusan
¡ Aturan pengambilan keputusan merupakan pernyataan
mengenai kondisi di mana hipotesis nol ditolak dan kondisi di mana hipotesis
nol tidak ditolak.
Gambar berikut menggambarkan
daerah penolakan untuk suatu uji taraf nyata :

Perhatikan dalam gambar di atas
bahwa :
l Daerah di mana hipotesis nol tidak ditolak mencakup
daerah di sebelah kiri 1,645.
l Daerah penolakan adalah di sebelah kanan dari 1,645.
l Diterapkan suatu uji satu arah.
l Taraf nyata 0,05 dipilih.
l Nilai 1,645 memisahkan daerah-daerah dimana hipotesis
nol ditolak dan di mana hipotesis nol tidak ditolak.
Nilai 1,645 dinamakan nilai
kritis.
Langkah 5 :
Mengambil keputusan
¡ Langkah terakhir dalam uji statistik adalah mengambil
keputusan untuk menolak atau tidak menolak hipotesis nol.
¡ Keputusan menolak hipotesis nol karena nilai uji
statistik terletak di daerah penolakan.
Hasil ini merupakan
rekomendasi berdasarkan bukti-bukti sampel yang dapat diberikan peneliti kepada
manajer puncak sebagai pembuat keputusan, tetapi keputusan akhir biasanya tetap
diambil oleh manajer puncak tersebut.
Uji Satu Arah dan Uji Dua
Arah
Uji satu arah :
¡ Bila hipotesis nol H0 : q = q0
dilawan dengan hipotesis alternatif H1 : q > q0
atau H1 : q < q0
¡ Uji satu arah ditandai dengan adanya satu daerah
penolakan hipotesis nol yang bergantung pada nilai kritis tertentu.
¡ Nilai kritis diperoleh dari tabel untuk nilai a yang telah dipilih sebelumnya.
Uji dua arah
¡ Bila hipotesis nol H0 : q = q0
dilawan dengan hipotesis alternatif H1 : q ¹ q0 .
¡ Uji dua arah ditandai dengan adanya dua daerah penolakan
hipotesis nol yang juga bergantung pada nilai kritis tertentu.
¡ Nilai kritis ini diperoleh dari tabel untuk nilai a/2 yang telah dipilih sebelumnya.
Uji menyangkut rata-rata:


Uji Menyangkut Proporsi

Uji Menyangkut Variansi

Daftar Pustaka:
Sugiyono, 2012. Statistika
unntuk penelitian. Bandung: Alfabeta